研究目的
本项目旨在开发一个旅游热门城市分析系统,通过对国内外相关数据进行收集、整理和分析,为用户提供有关旅游热门城市的实时信息和推荐服务。
开发背景
随着互联网技术的发展,越来越多的人选择在线查询和预订旅行服务。然而,面对海量的旅游信息,用户往往难以找到符合自己需求的热门城市。因此,开发一个能够快速、准确地分析旅游热门城市的系统具有重要意义。
国外研究现状分析
在国外,已经有一些类似的旅游热门城市分析系统。例如,TripAdvisor(猫途鹰)是一个全球性的旅游网站,提供酒店、餐厅、景点等信息,并根据用户的评价和浏览量对热门城市进行排名。此外,Google Trends(谷歌趋势)也是一个常用的数据分析工具,可以分析搜索热度和趋势,帮助用户了解不同地区的旅游热点。
国内研究现状分析
在国内,虽然也有一些旅游热门城市分析系统,但大多数都是基于单一来源的数据,如政府发布的统计数据或旅游局提供的报告。这些系统往往缺乏实时性和个性化推荐功能。此外,由于数据质量和准确性的问题,这些系统的分析结果也难以得到广泛认可。
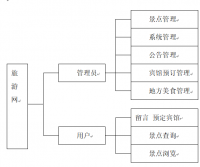
需求分析
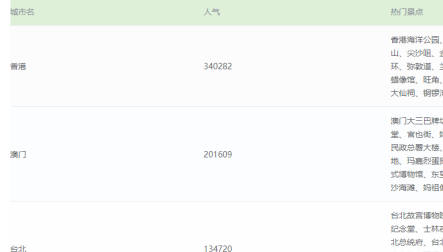
收集国内外旅游热门城市的相关信息,包括景点、酒店、餐厅、交通等。
对收集到的数据进行清洗、整理和分析,生成可视化的报表和图表。
根据用户的地理位置、兴趣爱好等信息,为用户提供个性化的旅游推荐服务。
支持用户对推荐结果进行评分和反馈,以便不断优化推荐算法。
方案分析
本项目采用以下技术实现:
数据爬取:使用Python编写爬虫程序,从各大旅游网站获取相关数据。
数据库设计:使用MySQL数据库存储和管理数据。
Web框架:使用Flask作为后端框架,处理用户请求和数据交互。
数据分析:使用Pandas库对数据进行清洗、整理和分析。
数据可视化:使用Matplotlib和Seaborn库生成各种图表和报表。
推荐算法:使用协同过滤算法为用户提供个性化推荐服务。
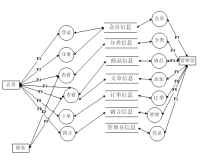
本系统的设计方案包括以下几个步骤:
1. 数据爬取:从各个旅游网站和用户评价中收集相关数据;
2. 数据清洗和处理:对收集到的数据进行清洗和处理,提取相关特征;
3. 数据分析和建模:使用机器学习和数据挖掘技术对数据进行分析和建模,提取有用的旅游信息;
4. 系统开发:使用Web开发技术构建系统界面和功能;
5. 数据可视化:通过图表、地图等可视化方式展示数据结果;
6. 系统测试和优化:对系统进行测试和性能优化。
创新点:
本系统的创新点主要体现在以下几个方面:
1. 综合多个数据源:通过收集和整合来自多个旅游网站和用户评价的数据,提供更全面和客观的旅行信息。
2. 个性化推荐:根据用户的偏好和历史记录,提供个性化的旅游推荐,帮助用户更好地选择旅行目的地和行程安排。
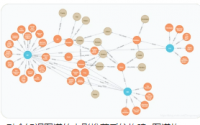
3. 数据可视化:通过图表、地图等可视化方式展示数据结果,帮助用户更直观地理解旅游目的地的情况。
与传统的旅游信息平台相比,本系统的创新点如下:
(1)个性化推荐服务:本系统采用协同过滤、内容过滤等算法为用户提供个性化的旅游推荐服务,满足用户不同的需求和偏好;
(2)实时数据分析:本系统通过实时监测和分析数据的变化趋势,帮助用户及时了解旅游业的发展动态;
(3)多维度的数据分析:本系统不仅可以从景点、酒店等维度进行分析,还可以从用户评价等维度进行分析,为用户提供更加全面的数据支持。
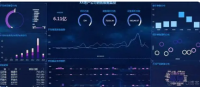
数据可视化:
为了便于用户理解和使用本系统,需要对数据进行可视化展示。具体包括以下内容:
(1)数据报表:根据不同的数据源和分析结果生成各种报表,如折线图、柱状图、散点图等;
(2)推荐列表:根据用户的偏好和需求生成推荐列表,包括景点、酒店、机票等信息;
(3)用户评价展示:展示用户的评价和留言信息,帮助用户了解产品的优缺点;
(4)数据分享:支持将数据分析结果导出为Excel、PDF等格式的文件,便于用户进行分享和使用。
数据爬取开发过程:
为了保证数据质量和完整性,本系统需要进行数据爬取开发过程。具体包括以下步骤:
(1)确定爬取目标网站和数据源;
(2)分析目标网站的结构和特点,设计合适的爬虫程序;
(3)使用Python等技术编写爬虫程序并进行测试;
(4)定期更新爬取的数据,保证数据的实时性和准确性。