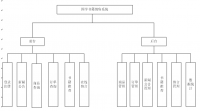
研究目的:
本研究旨在开发一个基于Python的书籍推荐系统,通过分析用户的阅读兴趣和行为,为用户提供个性化的书籍推荐,以提升用户阅读体验和满足用户的阅读需求。
开发背景:
随着互联网的迅猛发展,读书已经不再局限于纸质书籍,越来越多的人开始借助网络平台进行阅读。然而,用户在面对庞大的图书信息时,往往难以找到符合自己兴趣和偏好的书籍。因此,开发一个高效准确的书籍推荐系统对于提升用户体验和推动书籍消费具有重要意义。
国外研究现状分析:
在国外,已经有许多基于Python开发的书籍推荐系统应用于实际生活中,如Amazon的推荐算法、Goodreads的个性化推荐系统等。这些系统主要基于用户的历史阅读记录、购买习惯、评分和评论等信息来进行推荐,使用了协同过滤、内容过滤和混合推荐等推荐算法,取得了较好的效果。
国内研究现状分析:
国内的书籍推荐系统研究相对较少,目前主要集中在大型电商平台的商品推荐领域。由于电商平台具有大量用户行为数据和丰富的商品信息,使得基于Python的书籍推荐系统在国内也具备较好的应用前景。
需求分析:
根据研究目的和开发背景,本书籍推荐系统需要具备以下主要功能:
1. 用户注册与登录: 用户可以通过注册与登录功能进行账号管理。
2. 书籍信息展示: 系统需要展示图书库中的书籍信息,包括书籍封面、书名、作者、出版社等。
3. 个性化推荐: 系统需要根据用户的阅读历史和行为,为其提供个性化的书籍推荐。
4. 搜索功能: 用户可以通过关键词搜索书籍并获取相应的搜索结果。
5. 评分和评论功能: 用户可以对已阅读的书籍进行评分和评论,以便其他用户参考。
6. 用户管理功能: 系统需要提供用户管理功能,包括用户信息的修改和删除等。
方案分析:
基于Python的书籍推荐系统可以采用以下方案实现:
1. 数据爬取: 利用Python的爬虫技术抓取图书信息,包括书籍封面、书名、作者、出版社等,并将数据存储到数据库中。
2. 推荐算法: 使用协同过滤、内容过滤和混合推荐等推荐算法来实现个性化推荐功能。
3. 框架搭建: 使用Flask作为Web框架搭建系统的前后端交互界面。
4. 数据库管理: 使用Mysql作为数据库管理系统,存储用户信息、书籍信息、评分和评论等数据。
可行性分析:
基于Python的书籍推荐系统的开发具有较高的可行性:
1. 技术支持:Python在数据处理和机器学习领域具有广泛的应用和丰富的资源和库,提供了强大的技术支持。
2. 数据来源:互联网上存在大量的公开书籍信息数据库,可以通过爬虫技
术获取相关数据,并实时更新。
3. 用户需求:用户对于个性化阅读的需求不断增长,基于Python的书籍推荐系统可以满足用户的需求,提供精准的推荐结果。
4. 商业前景:随着数字阅读市场的扩大,基于Python的书籍推荐系统具有广阔的商业前景,可以吸引用户并推动书籍销售。
数据可视化:
为了提升用户体验和可视化展示数据,可以使用Python的数据可视化库,如Matplotlib或Seaborn,对推荐结果、用户评分和评论等数据进行可视化分析,生成直观清晰的图表和图形,帮助用户更好地理解和使用推荐系统。
创新点:
本书籍推荐系统的创新点包括:
1. 个性化推荐算法:采用协同过滤、内容过滤和混合推荐等多种推荐算法进行个性化推荐,提高推荐准确度和用户满意度。
2. 数据爬取和实时更新:通过爬虫技术从多个书籍信息源获取数据,并实时更新图书库,保证数据的准确性和实用性。
3. 数据可视化分析:利用数据可视化技术对推荐结果、用户评分和评论等数据进行可视化分析,提供更直观的用户体验和数据展示。
数据爬取开发过程:
数据爬取开发过程包括以下步骤:
1. 确定数据源:选择适合的在线书籍信息源,如豆瓣读书、亚马逊等。
2. 确定爬虫目标:确定需要抓取的数据字段,如书籍封面、书名、作者、出版社等。
3. 编写爬虫程序:使用Python的爬虫框架或库,如Scrapy或BeautifulSoup,编写爬虫程序,根据页面结构及其类似的URL模式,抓取目标数据并保存到数据库中。
4. 数据清洗和预处理:对于抓取到的数据,进行清洗和预处理,确保数据的准确性和一致性。
5. 定时更新:通过设置定时任务,定期执行爬虫程序,保持书籍信息库的实时更新。
推荐算法:
基于Python的书籍推荐系统可以采用以下推荐算法:
1. 协同过滤:根据用户的阅读历史和行为,找出与当前用户兴趣相似的其他用户,然后根据这些用户的阅读记录为当前用户进行推荐。
2. 内容过滤:通过分析书籍的内容特征,如标签、分类、主题等,为用户推荐与其兴趣相似的书籍。
3. 混合推荐:综合利用协同过滤和内容过滤的方法,提供更准确和全面的推荐结果。
协同过滤推荐算法是一种常用的推荐算法,它通过分析用户的历史行为数据,找到与目标用户兴趣相似的其他用户,然后根据这些相似用户的喜好来为目标用户推荐书籍。具体实现步骤如下:
数据预处理:将用户的历史行为数据进行预处理,包括去除无效数据、归一化等操作。
计算用户相似度:根据用户的历史行为数据,计算每个用户与其他用户之间的相似度。常用的相似度计算方法有皮尔逊相关系数、余弦相似度等。
选择推荐物品:根据目标用户的相似度得分,从所有物品中选择最相似的几个物品作为推荐结果。
评估推荐效果:使用一些评价指标来评估推荐效果,如准确率、召回率、F1值等。
框架搭建:
本项目需要使用以下技术:
1. Flask:作为Web框架搭建系统的前后端交互界面,实现用户注册、登录、书籍展示等功能。
2. Mysql:作为数据库管理系统,存储用户信息、书籍信息、评分和评论等数据,提供数据存储和查询功能。
需求分析:本项目需要实现以下功能:
a. 用户注册和登录;
b. 用户填写个人资料,包括年龄、性别、职业等信息;
c. 用户浏览书籍列表;
d. 根据用户的阅读历史和兴趣偏好,为用户推荐适合其阅读的书籍;
e. 支持用户对推荐结果进行评分和评论。
方案分析:本项目采用Flask作为Web框架,使用MySQL作为数据库存储用户信息和书籍信息。同时,我们将采用协同过滤算法来实现书籍推荐功能。具体流程如下:
a. 用户注册和登录;
b. 用户填写个人资料;
c. 爬取图书信息并存储到数据库中;
d. 根据用户的阅读历史和兴趣偏好,计算用户的协同过滤因子;
e. 根据协同过滤因子为用户推荐适合其阅读的书籍;
f. 支持用户对推荐结果进行评分和评论。