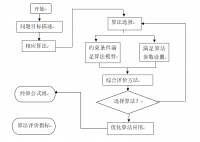
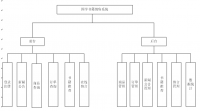
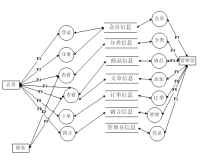
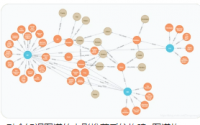
研究目的:
本系统的研究目的是设计和实现一个基于关联规则算法的小说类书籍推荐系统,以帮助读者发现他们可能感兴趣的新书籍,并提高读者的阅读体验。该系统将通过对用户的历史购买记录和阅读行为进行分析,以及书籍之间的关联规则,为用户提供个性化的推荐服务。
开发背景:
随着互联网的普及和数字化阅读的兴起,越来越多的读者通过在线平台获取和购买书籍。然而,许多读者在选择书籍时可能会遇到困难,因为他们可能不了解新的书籍或不确定是否会喜欢它们。因此,一个准确、个性化的书籍推荐系统对于帮助读者发现新书籍和提高阅读体验非常重要。
国外研究现状分析:
在国外,许多科技公司和研究机构已经对书籍推荐系统进行了广泛的研究和应用。其中,一些知名的公司如Amazon、Goodreads等已经在其在线书店中提供了基于协同过滤和关联规则的推荐服务。此外,一些研究机构如Cornell University、University of California等也在推荐系统的算法和模型方面取得了重要进展。
国内研究现状分析:
在国内,随着互联网和数字化阅读的快速发展,对于书籍推荐系统的需求也越来越大。然而,与国外相比,国内在这方面的研究和应用相对较少。因此,设计和实现一个基于关联规则算法的小说类书籍推荐系统具有重要的实际意义和学术价值。
需求分析:
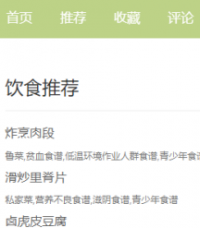
本系统的用户主要包括读者和图书管理人员。读者需要能够浏览和搜索小说类书籍,查看推荐列表,并能够购买或添加书籍到购物车中。图书管理人员需要能够添加、编辑和管理书籍信息,包括书名、作者、出版社、价格等。此外,系统还需要实现以下功能:
数据爬取:从第三方数据源获取小说类书籍信息,包括书名、作者、出版社、价格等。
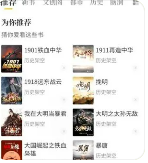
推荐算法:使用关联规则算法对用户历史购买记录和阅读行为进行分析,计算用户对书籍的兴趣程度,并生成个性化推荐列表。
数据可视化:通过数据可视化工具展示推荐结果、用户历史购买记录和阅读行为数据等。
用户管理:为读者提供账户管理功能,包括登录、注册、修改个人信息等。
数据分析:对用户行为数据进行分析,以评估推荐系统的效果和优化算法。
方案分析:
本系统的设计方案包括以下步骤:
数据爬取:使用Python编写爬虫程序,从第三方数据源获取小说类书籍信息,并将数据保存到数据库中。
数据预处理:对爬取到的数据进行清洗、整理和转换,以便于后续的推荐算法处理。
推荐算法:使用关联规则算法对用户历史购买记录和阅读行为进行分析,计算用户对书籍的兴趣程度,并生成个性化推荐列表。
数据库设计:设计合适的数据库表结构,以存储用户信息、书籍信息、购买记录等数据。
推荐系统实现:使用Flask框架搭建Web应用程序,将推荐算法与数据库结合,实现一个完整的书籍推荐系统。
数据可视化:使用数据可视化工具(如matplotlib、seaborn等)展示推荐结果、用户历史购买记录和阅读行为数据等。
用户管理:实现用户登录、注册、修改个人信息等功能,确保用户信息的安全性和完整性。
数据分析:通过对用户行为数据进行分析,评估推荐系统的效果和优化算法。
可行性分析:
本系统的可行性较高,原因如下:
技术可行性:本系统将采用Python语言编写爬虫程序和Web应用程序,使用MySQL数据库存储数据。这些技术都是成熟的、广泛使用的,具有较高的可靠性。
时间和资源可行性:本系统的开发周期为6个月左右,需要具备一定经验和技能的开发人员参与。在资源和资金方面,需要购买硬件设备和数据库软件等必要的资源投入。
法律和合规性可行性:在数据爬取方面,需要遵守相关法律法规和网站的使用条款,以避免侵犯知识产权和其他法律问题。在用户隐私方面,需要确保用户的个人信息受到保护,并遵守相关的隐私政策和法规。
市场和商业可行性:本系统将为读者提供个性化的书籍推荐服务,有助于提高读者的阅读体验和购买满意度。同时,对于图书管理人员来说,本系统将提供方便的管理工具和功能,降低管理成本和提高效率。因此,本系统在市场和商业上具有可行性。
创新点:本系统的创新点主要体现在以下几个方面:1.采用关联规则算法进行推荐,能够捕捉到商品之间的关联性。2.综合考虑用户的阅读行为和偏好,为用户生成个性化的推荐结果。3.利用数据可视化技术,提供直观清晰的推荐结果展示。
数据爬取开发过程:为了获取书籍信息和用户行为数据,我们需要进行数据爬取。具体的开发过程包括以下几个步骤:1.确定需要爬取的网站和数据结构。2.使用爬虫工具或编写爬虫程序进行网页数据抓取。3.对抓取到的数据进行清洗和处理。4.将清洗后的数据存储到数据库中,供推荐算法使用。
本系统的研究目的是设计和实现一个基于关联规则算法的小说类书籍推荐系统,以帮助读者发现他们可能感兴趣的新书籍,并提高读者的阅读体验。该系统将通过对用户的历史购买记录和阅读行为进行分析,以及书籍之间的关联规则,为用户提供个性化的推荐服务。
开发背景:
随着互联网的普及和数字化阅读的兴起,越来越多的读者通过在线平台获取和购买书籍。然而,许多读者在选择书籍时可能会遇到困难,因为他们可能不了解新的书籍或不确定是否会喜欢它们。因此,一个准确、个性化的书籍推荐系统对于帮助读者发现新书籍和提高阅读体验非常重要。
国外研究现状分析:
在国外,许多科技公司和研究机构已经对书籍推荐系统进行了广泛的研究和应用。其中,一些知名的公司如Amazon、Goodreads等已经在其在线书店中提供了基于协同过滤和关联规则的推荐服务。此外,一些研究机构如Cornell University、University of California等也在推荐系统的算法和模型方面取得了重要进展。
国内研究现状分析:
在国内,随着互联网和数字化阅读的快速发展,对于书籍推荐系统的需求也越来越大。然而,与国外相比,国内在这方面的研究和应用相对较少。因此,设计和实现一个基于关联规则算法的小说类书籍推荐系统具有重要的实际意义和学术价值。
需求分析:
本系统的用户主要包括读者和图书管理人员。读者需要能够浏览和搜索小说类书籍,查看推荐列表,并能够购买或添加书籍到购物车中。图书管理人员需要能够添加、编辑和管理书籍信息,包括书名、作者、出版社、价格等。此外,系统还需要实现以下功能:
数据爬取:从第三方数据源获取小说类书籍信息,包括书名、作者、出版社、价格等。
推荐算法:使用关联规则算法对用户历史购买记录和阅读行为进行分析,计算用户对书籍的兴趣程度,并生成个性化推荐列表。
数据可视化:通过数据可视化工具展示推荐结果、用户历史购买记录和阅读行为数据等。
用户管理:为读者提供账户管理功能,包括登录、注册、修改个人信息等。
数据分析:对用户行为数据进行分析,以评估推荐系统的效果和优化算法。
方案分析:
本系统的设计方案包括以下步骤:
数据爬取:使用Python编写爬虫程序,从第三方数据源获取小说类书籍信息,并将数据保存到数据库中。
数据预处理:对爬取到的数据进行清洗、整理和转换,以便于后续的推荐算法处理。
推荐算法:使用关联规则算法对用户历史购买记录和阅读行为进行分析,计算用户对书籍的兴趣程度,并生成个性化推荐列表。
数据库设计:设计合适的数据库表结构,以存储用户信息、书籍信息、购买记录等数据。
推荐系统实现:使用Flask框架搭建Web应用程序,将推荐算法与数据库结合,实现一个完整的书籍推荐系统。
数据可视化:使用数据可视化工具(如matplotlib、seaborn等)展示推荐结果、用户历史购买记录和阅读行为数据等。
用户管理:实现用户登录、注册、修改个人信息等功能,确保用户信息的安全性和完整性。
数据分析:通过对用户行为数据进行分析,评估推荐系统的效果和优化算法。
可行性分析:
本系统的可行性较高,原因如下:
技术可行性:本系统将采用Python语言编写爬虫程序和Web应用程序,使用MySQL数据库存储数据。这些技术都是成熟的、广泛使用的,具有较高的可靠性。
时间和资源可行性:本系统的开发周期为6个月左右,需要具备一定经验和技能的开发人员参与。在资源和资金方面,需要购买硬件设备和数据库软件等必要的资源投入。
法律和合规性可行性:在数据爬取方面,需要遵守相关法律法规和网站的使用条款,以避免侵犯知识产权和其他法律问题。在用户隐私方面,需要确保用户的个人信息受到保护,并遵守相关的隐私政策和法规。
市场和商业可行性:本系统将为读者提供个性化的书籍推荐服务,有助于提高读者的阅读体验和购买满意度。同时,对于图书管理人员来说,本系统将提供方便的管理工具和功能,降低管理成本和提高效率。因此,本系统在市场和商业上具有可行性。
创新点:本系统的创新点主要体现在以下几个方面:1.采用关联规则算法进行推荐,能够捕捉到商品之间的关联性。2.综合考虑用户的阅读行为和偏好,为用户生成个性化的推荐结果。3.利用数据可视化技术,提供直观清晰的推荐结果展示。
数据爬取开发过程:为了获取书籍信息和用户行为数据,我们需要进行数据爬取。具体的开发过程包括以下几个步骤:1.确定需要爬取的网站和数据结构。2.使用爬虫工具或编写爬虫程序进行网页数据抓取。3.对抓取到的数据进行清洗和处理。4.将清洗后的数据存储到数据库中,供推荐算法使用。