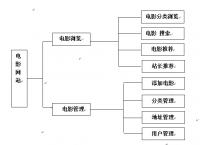
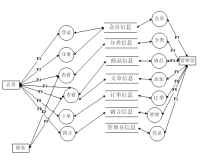
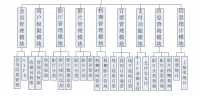
基于Python的电影分析与推荐项目可以分为以下几个部分:
研究目的:
本项目旨在开发一个电影分析与推荐系统,通过分析用户的历史观影记录和评分数据,为用户提供个性化的电影推荐。
电影分析和推荐系统的研究目的是为了帮助观众发现和欣赏他们可能喜欢的电影,同时为电影制片方提供有关观众喜好的洞察。通过使用数据分析和机器学习算法,我们可以更好地理解观众的观影偏好,从而为他们提供更精确和个性化的电影推荐。
开发背景:
随着互联网的普及,越来越多的人选择在线观看电影。然而,如何找到符合个人口味的电影仍然是一个挑战。因此,开发一个智能的电影推荐系统具有很大的市场需求。
随着互联网和数字化媒体的普及,观众对于电影的需求和偏好也在不断变化。电影分析和推荐系统的开发,可以帮助观众在海量的电影资源中找到他们感兴趣的内容。同时,对于电影制片方来说,通过使用此类系统,他们可以更好地了解观众的喜好和需求,以便制定更有效的营销策略。
国外研究现状分析:
在国外,对于电影分析和推荐系统的研究已经进行了较长一段时间。其中,一些知名的电影推荐网站包括IMDb、Netflix和Amazon Prime等。这些网站使用各种算法和数据来源,为观众提供个性化的电影推荐。例如,IMDb使用用户评分和评论来了解用户的喜好,而Netflix则使用用户的观影历史、行为和喜好来构建其著名的推荐算法。
国内研究现状分析:
在国内,电影推荐系统的研究也取得了一定的成果。例如,中国科学院计算技术研究所提出了一种基于深度学习的电影推荐方法。此外,还有一些针对特定场景的电影推荐系统,如基于社交网络的电影推荐系统等。
近年来,随着国内电影市场的快速发展,对于电影分析和推荐系统的研究也逐渐得到了关注。一些在线电影平台,如爱奇艺、腾讯视频和优酷等,也开始提供基于用户行为的电影推荐服务。然而,与国外相比,国内的电影推荐系统在算法、数据质量和个性化推荐方面仍存在一定的差距。
需求分析:
数据收集和分析:我们需要从各种来源收集电影数据,如电影数据库、社交媒体和用户评论等,然后对这些数据进行清洗和分析。
用户行为分析:我们需要通过分析用户的观影历史、行为和偏好来了解他们的喜好和兴趣。
推荐算法:我们需要根据用户的喜好和行为,使用合适的算法来生成个性化的电影推荐。
数据可视化:我们需要将数据以可视化的方式呈现给用户,以便他们更好地理解我们的推荐结果。
用户界面设计:我们需要设计一个友好、易于使用的用户界面,以便用户可以轻松地使用我们的系统。
方案分析:
本项目采用Flask作为Web框架,使用MySQL作为数据库存储用户观影记录和评分数据。同时,结合机器学习和深度学习技术,实现基于协同过滤、矩阵分解等推荐算法的电影推荐功能。
数据收集和处理:我们可以使用Python中的各种库(如BeautifulSoup、Pandas和NumPy)来收集和处理数据。同时,我们还可以使用数据仓库来存储和管理我们的数据。
用户行为分析:我们可以使用Python中的机器学习库(如Scikit-learn)来训练模型,以预测用户的喜好和兴趣。我们还可以使用无监督学习算法(如聚类分析)来识别观众群体和他们的共同特征。
推荐算法:我们可以采用协同过滤算法、内容过滤算法或者混合过滤算法来生成电影推荐。这些算法可以通过Python中的机器学习库(如Scikit-learn)来实现。
数据可视化:我们可以使用Python中的数据可视化库(如Matplotlib和Seaborn)来呈现数据和推荐结果。同时,我们还可以使用前端开发技术(如HTML、CSS和JavaScript)来构建交互式的数据可视化界面。
用户界面设计:我们可以使用Flask等Web框架来搭建我们的网站,并使用HTML、CSS和JavaScript等前端技术来设计用户界面。同时,我们还需要考虑用户界面的交互性和易用性,以便用户能够轻松地使用我们的系统。
可行性分析:
数据收集和处理:我们需要确保能够从各个来源收集到准确、完整的数据,并使用合适的方法对数据进行清洗和处理。同时,我们还需要考虑到数据存储和处理所需的计算资源和时间成本。
用户行为分析:我们需要确保能够准确地追踪和分析用户的观影历史、行为和偏好。此外,我们还需要考虑到用户隐私保护和数据安全问题。
推荐算法:我们需要选择合适的算法来生成个性化的电影推荐,并确保算法的准确性和可靠性。同时,我们还需要考虑到算法的计算复杂度和性能要求。
数据可视化:我们需要确保数据可视化的准确性和可读性,以便用户能够更好地理解我们的推荐结果。同时,我们还需要考虑到数据可视化的美观性和交互性。
用户界面设计:我们需要确保用户界面的易用性和友好性,以便用户能够轻松地使用我们的系统。同时,我们还需要考虑到用户界面的可维护性和可扩展性。
数据爬取开发过程:
选择合适的爬虫工具:根据不同的数据来源和需求,选择合适的爬虫工具进行数据爬取。例如,对于网页数据的爬取可以使用BeautifulSoup或Scrapy等工具;对于API数据的爬取可以使用Requests或Urllib等库。
数据获取:使用Python的网络爬虫技术,从电影数据库、电影网站或API获取电影数据。可以获取电影的标题、类型、导演、演员、剧情简介、评分等信息。
数据清洗和整理:对获取的电影数据进行清洗和格式化,去除重复数据、处理缺失值,并将数据整理成适合分析和推荐的结构。
数据分析:使用Python的数据分析库,如Pandas和NumPy,对电影数据进行统计分析和特征提取。可以分析电影的受欢迎程度、评分分布、不同类型电影的数量等。
数据可视化:使用Python的数据可视化库,如Matplotlib和Seaborn,将分析结果可视化,生成各种图表和图像。例如,可以绘制电影类型的饼图、评分的柱状图等。
推荐算法:选择合适的推荐算法来为用户推荐电影。常用的推荐算法包括基于内容的推荐、协同过滤推荐和深度学习推荐等。可以使用Python的机器学习库,如scikit-learn和TensorFlow,来实现这些算法。