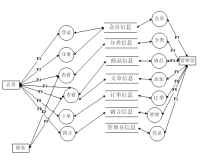
研究目的:
本研究旨在开发一个基于Python的网络小说受欢迎程度分析及可视化系统,通过分析网络小说的阅读量、评分、评论和收藏等数据,评估网络小说的受欢迎程度,并使用数据可视化技术展示分析结果,帮助读者了解和选择高质量的网络小说。
开发背景:
随着互联网和移动互联网的发展,网络小说越来越受到读者的关注和喜爱。然而,网络小说数量庞大且质量良莠不齐,读者往往难以判断一部网络小说的受欢迎程度和质量。因此,开发一个基于Python的网络小说受欢迎程度分析及可视化系统对于帮助读者选择优质网络小说具有重要意义。
国外研究现状分析:
在国外,已经有一些基于Python的文本分析和数据可视化工具应用于网络小说的受欢迎程度分析领域。例如,使用Python的自然语言处理技术对网络小说的评论和评分进行情感分析,以评估网络小说的受欢迎程度。然后,使用数据可视化技术展示分析结果,帮助读者了解和选择适合的网络小说。
国内研究现状分析:
国内对于基于Python的网络小说受欢迎程度分析及可视化的研究相对较少,目前主要集中在文本分析和情感分析领域。然而,对于数据可视化的应用较少,并且缺乏专门针对网络小说的受欢迎程度分析的工具和系统。
需求分析:
根据研究目的和开发背景,本网络小说受欢迎程度分析及可视化系统需要具备以下主要功能:
1. 数据爬取:从网络小说平台获取网络小说的基本信息、阅读量、评分、评论和收藏等数据,并保存到数据库中。
2. 受欢迎程度分析:针对网络小说的阅读量、评分和收藏等数据,计算和评估网络小说的受欢迎程度。
3. 数据可视化:使用Python的数据可视化库,如Matplotlib和Seaborn,对受欢迎程度分析结果进行可视化展示,生成直观清晰的图表和图形。
4. 用户界面:使用Flask作为Web框架搭建系统的前后端交互界面,实现用户注册、登录和数据查询等功能。
5. 数据库管理:使用Mysql作为数据库管理系统,存储网络小说的基本信息和分析结果等数据。
方案分析:
基于Python的网络小说受欢迎程度分析及可视化系统可以采用以下方案实现:
1. 数据爬取:使用Python的爬虫技术抓取网络小说平台上的网络小说信息,包括基本信息、阅读量、评分、评论和收藏等数据,并将数据存储到数据库中。
2. 受欢迎程度分析:根据网络小说的阅读量、评分和收藏等数据,设计评估模型,计算和评估网络小说的受欢迎程度,生成分析结果。
3. 数据可视化:使用Python的数据可视化库,如Matplotlib和Seaborn,对受欢迎程度分析结果进行可视化展示,生成直观清晰的图表和图形。
4. 用户界面:
4. 用户界面:使用Flask作为Web框架搭建系统的前后端交互界面,实现用户注册、登录和数据查询等功能。用户可以通过界面进行账号管理,查询网络小说的受欢迎程度分析结果,并查看可视化展示的图表和图形。
可行性分析:
基于Python的网络小说受欢迎程度分析及可视化系统的开发具有较高的可行性:
1. 技术支持:Python在数据处理、文本分析和数据可视化等领域具有广泛的应用和丰富的资源和库,提供了强大的技术支持。
2. 数据来源:网络小说平台上存在大量的网络小说信息和相关数据,可以通过爬虫技术获取相关数据,并进行分析和可视化处理。
3. 用户需求:读者对于了解网络小说的受欢迎程度和选择高质量网络小说的需求不断增长,基于Python的受欢迎程度分析及可视化系统可以满足读者的需求。
4. 商业前景:随着网络小说市场的扩大,基于Python的受欢迎程度分析及可视化系统具有广阔的商业前景,可以吸引读者并推动网络小说的阅读和销售。
数据可视化:
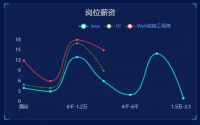
本项目可以使用Python的数据可视化库,如Matplotlib和Seaborn,对受欢迎程度分析的结果进行可视化展示。可以生成柱状图、折线图、饼图等图表,以及词云图等特殊的可视化图形,帮助读者更直观地了解网络小说的受欢迎程度和评估结果。
创新点:
本网络小说受欢迎程度分析及可视化系统的创新点包括:
1. 综合评估模型:通过综合利用网络小说的阅读量、评分和收藏等多种数据进行评估,得出对网络小说受欢迎程度的准确评估结果。
2. 数据可视化展示:使用Python的数据可视化库将分析结果以直观清晰的图表和图形展示给用户,提供更好的数据可视化体验。
3. 用户界面设计:通过使用Flask作为Web框架搭建用户界面,提供用户注册、登录和数据查询等功能,以便用户灵活使用和查询需要的信息。
数据爬取开发过程:
确定目标网站和爬取范围:首先需要确定要爬取的网络小说网站,并明确要爬取的数据范围,例如小说名称、作者、分类、评分等。
分析目标网站的结构:通过查看目标网站的源代码或使用浏览器开发者工具,了解网站的结构和页面布局,以便编写合适的爬虫程序。
编写爬虫程序:根据分析结果,编写Python爬虫程序,实现对目标网站数据的抓取。可以使用requests库发送HTTP请求,使用BeautifulSoup库解析HTML页面,提取所需数据。
存储数据:将抓取到的数据存储到数据库中,以便后续的数据分析和处理。可以使用MySQL、MongoDB等关系型或非关系型数据库。
设置反爬机制:为了避免被目标网站封禁,需要设置一些反爬机制,例如设置随机User-Agent、使用代理IP、限制访问频率等。
测试和优化:在实际运行过程中,需要不断测试和优化爬虫程序,确保数据的准确性和稳定性。可以针对不同的目标网站进行多次测试,逐步优化程序性能。