基于协同过滤算法的音乐推荐系统的设计和实现方案:
研究目的:
本系统旨在为用户提供个性化、精准的音乐推荐服务,通过分析用户的历史听歌行为和兴趣,向用户推荐符合其喜好的音乐,提升用户的音乐消费体验。
开发背景:
随着互联网的普及和音乐平台的发展,用户对于音乐的需求越来越大,同时也对音乐推荐系统的精准度和推荐质量提出了更高的要求。国外对于音乐推荐系统研究较早,已经有许多成熟的商业应用,如Spotify、Apple Music等,国内也有类似网易云音乐等知名平台。
由于平台上的音乐数量庞大,用户很难找到自己喜欢的音乐。因此,开发一个能够根据用户喜好推荐音乐的系统变得尤为重要。协同过滤算法是一种常用的推荐算法,它通过分析用户的历史行为数据来预测用户对未评分物品的喜好程度,从而实现个性化推荐。
国内外研究现状分析:
在国外,协同过滤算法已经被广泛应用于音乐推荐、电影推荐等领域。例如,Spotify、Last.fm等在线音乐平台都采用了协同过滤算法进行音乐推荐。此外,研究人员还提出了许多改进的协同过滤算法,如基于矩阵分解的协同过滤(MF-CF)、基于图模型的协同过滤(GCFS)等。
国内研究现状分析:
在国内,虽然协同过滤算法在音乐推荐领域的应用较为广泛,但仍存在一些问题,如计算效率低、冷启动困难等。近年来,国内学者开始关注这些问题,并提出了一些改进的协同过滤算法,如基于深度学习的协同过滤(DL-CF)、基于多目标优化的协同过滤(MOF)等。
需求分析:
本系统需要满足以下需求:
用户可以登录系统并进行听歌行为记录;
系统可以分析用户历史听歌行为,推荐符合用户兴趣的歌曲;
系统可以提供可视化界面展示推荐结果;
系统可以支持多种推荐方式(如基于用户的协同过滤、基于物品的协同过滤等)。
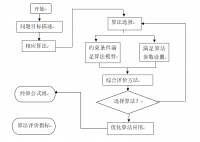
方案分析:
针对以上需求,本系统采用以下技术方案:
使用Flask框架搭建Web应用;
使用MySQL数据库存储用户信息和推荐结果;
使用协同过滤算法进行推荐;
使用数据可视化技术展示推荐结果。
可行性分析:
本系统具有以下可行性:
技术上可行:Flask框架和MySQL数据库都是成熟的技术,协同过滤算法也是常用的推荐算法之一;
经济上可行:本系统的开发成本较低,运行维护成本也相对较低;
时间上可行:本系统的开发周期较短,可以在预期时间内完成。
数据可视化:
为了更好地展示推荐结果,本系统将使用数据可视化技术,如图表、图像等,以清晰地呈现推荐结果和用户兴趣分布情况。
创新点:
本系统具有以下创新点:
结合协同过滤算法和数据可视化技术,提供更精准、个性化的音乐推荐服务;
引入多种推荐方式,满足不同用户的需求;
结合用户历史听歌行为和兴趣进行推荐,提高推荐准确度。
数据爬取开发过程:
本系统将通过以下步骤进行数据爬取:
确定数据来源和目标数据类型;
使用爬虫工具(如Scrapy)进行数据爬取;
对爬取的数据进行处理和清洗,去除无效数据和重复数据;
将处理后的数据存储到MySQL数据库中。
推荐算法:
本系统将采用以下几种推荐算法:
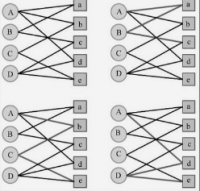
基于用户的协同过滤算法:通过分析用户历史听歌行为和其他用户的听歌行为,找到相似用户进行推荐;
基于物品的协同过滤算法:通过分析用户历史听歌行为和歌曲之间的相似度,向用户推荐相似的歌曲;
基于内容的推荐算法:通过分析歌曲的音频特征和文本信息,向用户推荐符合其喜好的歌曲。
本系统将采用基于协同过滤算法的推荐方法。具体而言,可以使用基于用户的协同过滤算法,通过计算用户之间的相似度来推荐相似用户喜欢的音乐。也可以使用基于内容的协同过滤算法,通过分析歌曲的特征和用户的喜好来进行推荐。可以根据具体情况选择合适的算法来进行推荐。