本研究旨在基于爬虫技术开发小说阅读网站,以实现推荐系统推算用户喜欢的小说,提高用户体验。具体目的如下:
- 探索利用爬虫技术进行小说信息的收集与处理。
- 研究并实现小说推荐算法,提高用户浏览体验。
- 构建一个完整的小说阅读网站,并测试其性能与可靠性。
研究意义:
随着互联网的快速发展,网络小说的阅读量逐年递增,用户的需求也日益多样化。传统的小说阅读网站往往只是提供简单的分类和搜索功能,无法满足用户的个性化需求。本研究将通过基于爬虫技术的小说阅读网站,为用户提供更加智能化的小说推荐服务,进一步提高用户体验和满意度,有利于小说行业的发展。
国外研究现状:
目前,国外已经有许多小说阅读网站采用了推荐系统,以提高用户体验。其中比较著名的有Goodreads、Amazon Kindle等。这些网站使用了基于协同过滤、基于内容过滤和基于深度学习等多种推荐算法,能够根据用户的历史阅读行为和兴趣偏好,为其推荐最适合的小说。
国内研究现状:
国内的小说阅读网站也开始逐步采用推荐系统,以提高用户体验。比较著名的有起点中文网、纵横中文网等。这些网站采用的推荐算法主要包括基于协同过滤、基于内容过滤和基于深度学习等。
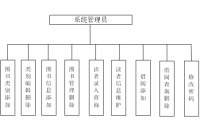
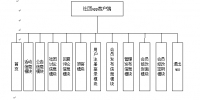
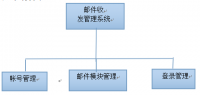
功能分析:
本小说阅读网站的主要功能包括:
- 注册与登录:用户可以注册并登录自己的账号。
- 小说分类:用户可以根据自己的喜好选择小说分类,如言情、武侠等。
- 小说搜索:用户可以通过关键字搜索自己喜欢的小说。
- 小说阅读:用户可以在线阅读小说,并设置阅读进度。
- 小说推荐:根据用户的历史阅读行为和兴趣偏好,为其推荐最适合的小说。
需求分析:
为了提高用户体验,本小说阅读网站需要满足以下需求:
- 用户体验友好:界面简洁明了,易于操作,提供良好的用户体验。
- 推荐算法准确:通过分析用户的历史阅读行为和兴趣偏好,准确推荐用户感兴趣的小说。
- 数据及时更新:爬虫需要定时更新小说信息,确保网站上的小说信息及时准确。
- 安全可靠:网站需要保障用户信息的安全,避免数据泄露等问题。
方案分析:
为实现小说阅读网站,本研究将采用Python语言开发,并使用Scrapy框架实现爬虫功能。针对小说推荐,将采用基于协同过滤的推荐算法,通过分析用户的阅读历史和兴趣偏好,推荐其可能感兴趣的小说。
在构建小说阅读网站时,需要考虑网站的用户体验,因此将采用简洁明了的界面设计,并提供多样化的小说分类和搜索功能。
可行性分析:
本研究使用的技术都是目前比较成熟和稳定的,因此技术实现上具有较高的可行性。同时,国内外已经有不少小说阅读网站采用了类似的技术,证明了其可行性和实用性。
技术分析:
本研究使用的技术包括Python语言、Scrapy框架、协同过滤算法等。Python作为一种简单易学的编程语言,具有较高的开发效率和代码可读性;Scrapy作为一个强大的爬虫框架,具有高度的灵活性和可扩展性;协同过滤算法则是一种经典的推荐算法,已被广泛应用于推荐系统中。
创新点:
本研究的创新点主要有以下几个方面:
- 基于爬虫技术的小说信息收集与处理,提高了小说信息的及时性和准确性。
- 基于协同过滤算法的小说推荐,能够更加准确地推荐用户感兴趣的小说。